
Generating Machine Images from CI
Recently I have been investigating different ways of implementing a deployment pipeline, part of the engineering discipline of continuous delivery. Particularly I’ve been looking at this in the context of systems running in the cloud. The advent of Infrastructure as a Service systems like Amazon’s EC2 has made it very easy for teams to spin up new servers within a matter of minutes. This reduction in lead time compared with traditional infrastructure means that it is easy for teams to scale up their applications to deal with increased demand, and also facilitates creating test and development environment that mirror production environments very closely. Differences in configuration between test and production environments have always been a major cause of bugs that are only caught in production - which is too late.
Systems like Amazon’s EC2 (Elastic Compute Cloud) allow us to start and run servers, paid for by the hour, based on saved machine images. In Amazon’s world these are called AMIs (Amazon Machine Images). We create an AMI by starting up a machine (an instance) running in the cloud with a basic configuration (based on another AMI), installing whatever software we need, and setting up our required configuration, and then saving a snapshot of this machine as a machine image. This is saved into the Simple Storage Service (S3), from where it can be read and used to start new instances.
I have been promoting the practice of creating AMIs as an output of the build process run by your continuous integration server. Traditionally teams have used CI servers to compile code and run tests, perhaps packaging it into an archive like a zip file ready for release. I suggest going one step further, starting up a machine in the cloud, copying this zip file to it, unpacking it, setting up any configuration necessary, and snapshotting that machine as an AMI, all as part of the build process. The artefact that is the output of the CI build is an AMI.
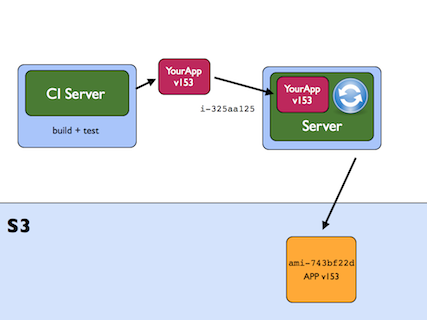
Once we have the AMI as the output of CI, it is easy to start up servers in a test or staging environment that we know are identical to those that will go into production - as we will launch them based on the same machine image. This gets rid of a whole class of problems to do with different operating system versions, libraries, or configuration options that may vary between test and production environments. This helps give us confidence in what we will release as we test in an environment almost identical to production.
If we use our AMIs together with Amazon autoscaling groups then we can effect deployment by having Amazon’s infrastructure replace old instances with new ones. An autoscaling group is a group if instances based on the same AMI. The infrastructure ensures that the group always contains at least a certain number of instances, so that if one should die for any reason a new one will be started to maintain the minimum group size. A launch configuration specifies the type of machine and the AMI that should be used, should the scaling group need to launch a new instance.
We can perform a deployment as follows. 1) create a new AMI as the output of CI, 2) create a new launch configuration referencing the new AMI, 3) update the scaling group to use the new launch configuration, 4) gradually kill off your old instances and wait for the scaling group to repopulate itself with instances based on the new AMI.
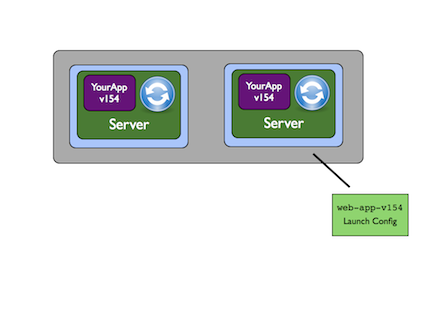
One of the benefits of this approach is that instances are started in the same way, whether they are launched as part of a deployment, or whether the size of the scaling group is increased and more instances are launched to deal with extra demand.
A slight drawback is that snapshotting and creating AMIs can take time, depending on the size of the disk image to be created, so if you are doing very frequent commits then it may net be efficient to create an AMI for every build. But, in an environment that is tending towards continuous deployment I think it works well.
I gave a talk at the Agile Cambridge conference last year that talks about this approach in more detail. The video is now available if you would like to hear more.